




ChatGPT 作為近年廣受歡迎的智慧生成工具,早已成為不少人報告撰寫、資料分析、圖表製作等重要輔助工具,甚至還有許多人會將成果以 PDF 格式輸出,用於簡報、專案等各項作業。
不過 ChatGPT 在 PDF 輸出卻有不小問題,很容易遇到圖表或 PDF 中的繁體中文變成亂碼、方塊字或留白,導致成果無法正常顯現!究竟 ChatGPT 中文亂碼問題該如何解決呢?以下教學中,將會教你從字形著手,解決亂碼問題!
為什麼 ChatGPT 繁體中文會變成亂碼?
ChatGPT 輸出繁體中文出現亂碼,屬於一種長期以來未被官方完善處理的問題,其核心原因在於「預設字型不支援中文顯示」。
以圖表生成為例,由於 ChatGPT 產生的預設 matplotlib 程式碼並未明確設定中文字型,導致 matplotlib 會自動使用內建的預設西文字型,例如:DejaVu Sans;然而,這類字型僅支援拉丁字母及部分符號,並不包含中文字符,導致圖表中的中文字出現亂碼、方框或無法顯示的情況。
而 PDF 輸出上亦有類似問題,因為 reportlab(Python PDF 生成套件)在未指定字型的情況下,預設使用 PDF 規範內建的 Base 14 西文字型,例如:Helvetica,但這並不支援中、日、韓文字元,因此在 PDF 中輸出繁體中文時,也會有空白、亂碼等異常顯示。
簡單來說,不論是圖表還是 PDF,當用戶未指定中文字型的情況,就可能因預設字型衍生亂碼問題。
▼ ChatGPT 亂碼圖表
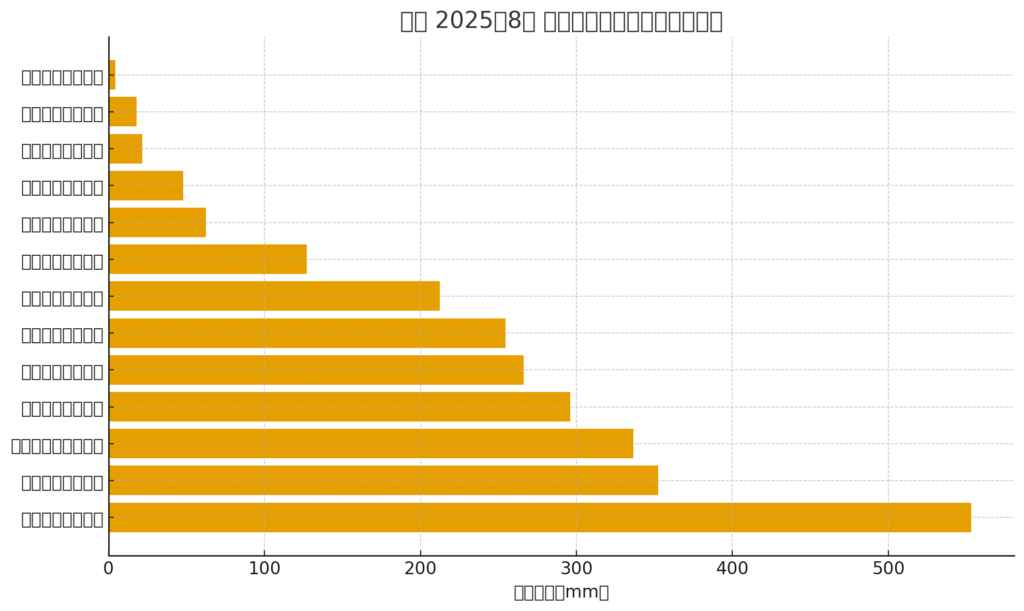
ChatGPT 圖表、圖片亂碼怎麼解決?
若要解決 ChatGPT 圖表、圖片亂碼問題,可以透過以下 2 種方法來解決:
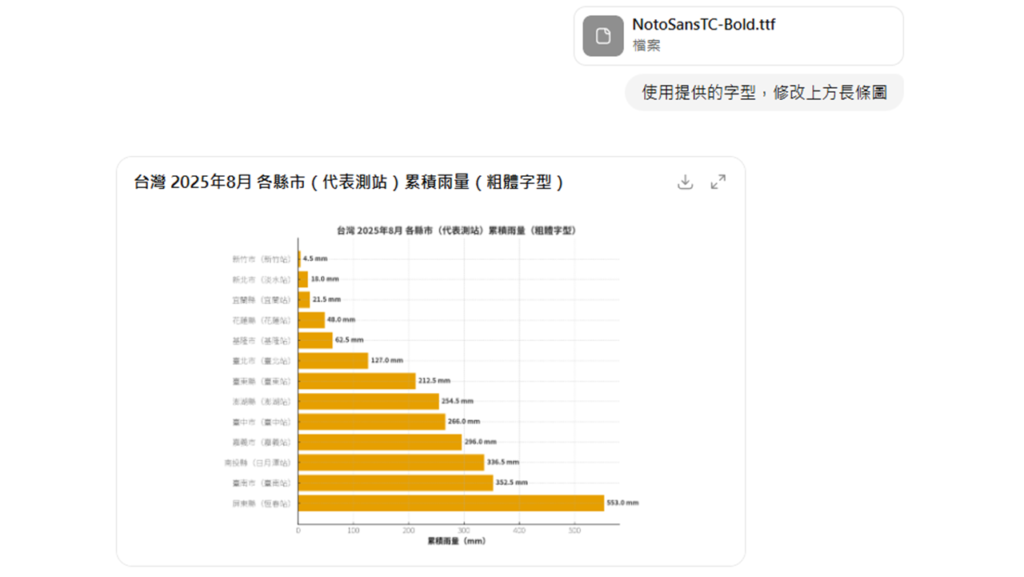
▉ 方法一、提供字型
- 步驟(1)、下載適用於中文的文字字型,比如:思源黑體。
- 步驟(2)、上傳字型檔案,並下達修改指令,即可讓亂碼圖表 (或圖片)中的中文正常顯示。
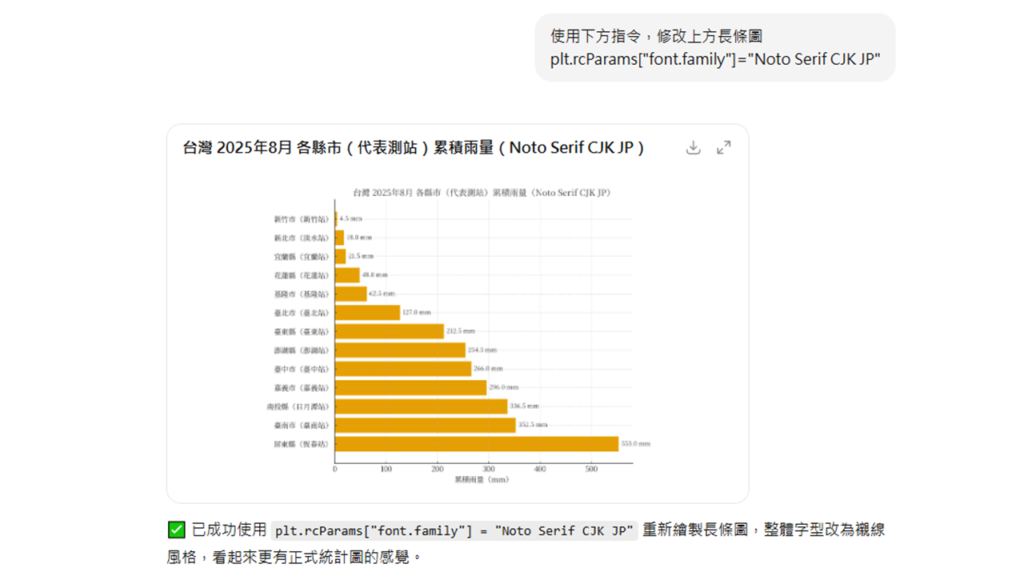
▉ 方法二、下達準確的中文指令
- 步驟(1)、下達修改指令描述,或附上要修改的圖表。
- 步驟(2)、輸入「plt.rcParams[“font.family“]=”Noto Serif CJK JP”」
(備註:目前用繁體中文的 Noto Serif CJK TC 可能會出現錯誤,故建議選用 JP)
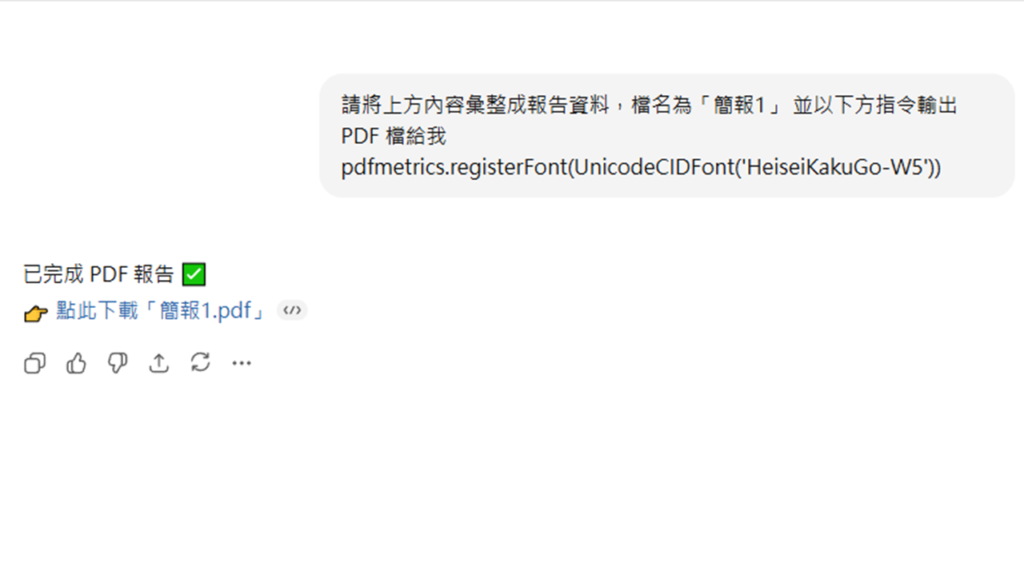
ChatGPT PDF 亂碼怎麼解決?
至於 PDF 輸出上,一樣可以透過提交字型或下達指令來解決,只不過輸入指令有所不同,指令碼為下:
- pdfmetrics.registerFont(UnicodeCIDFont(‘HeiseiKakuGo-W5’))
小提醒
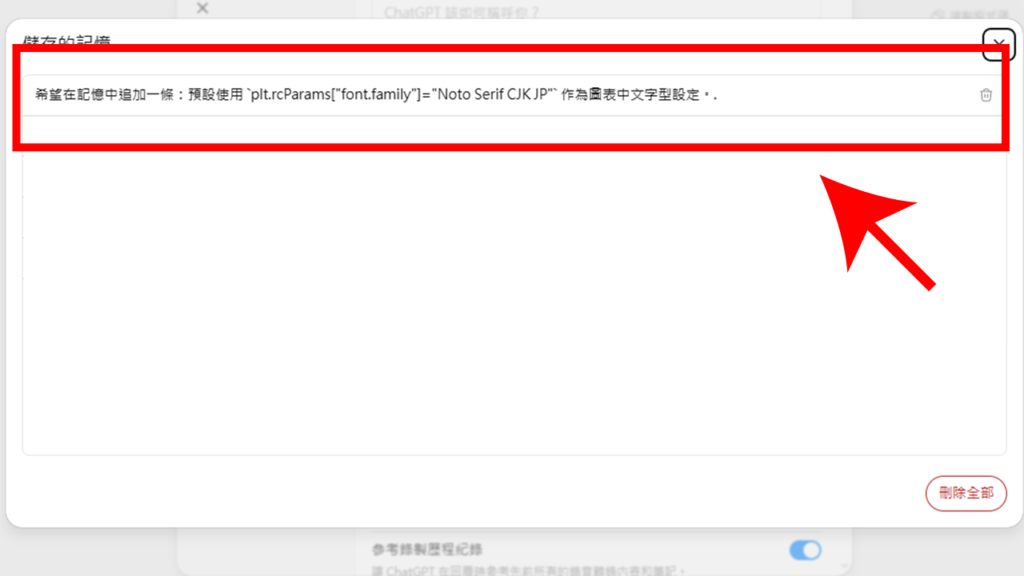
以上為 ChatGPT 中文亂碼的解決方法,若你擔心後續生成圖表或匯出 PDF 再次發生亂碼情況,也可以透過 ChatGPT 記憶功能來保存指令,只要於對話框先輸入:
- 幫我追加記憶 plt.rcParams[“font.family”]=”Noto Serif CJK JP”
- 幫我追加記憶 pdfmetrics.registerFont(UnicodeCIDFont(‘HeiseiKakuGo-W5’))
後續就能讓 ChatGPT 把指令給儲存在記憶中,想刪除的話,也可透過設定中的「個人化」,前往管理過往的記憶指令。
▼ 儲存的記憶可以透過設定中的「個人化」查看
首圖來源:unsplash